
Language is arguably humanity’s most consequential invention. Unlike any other species, Homo Sapiens has developed a means by which complicated, abstract plans can be efficiently and effectively transmitted from one mind to the next. Thus, our prehistoric ancestors, in contrast to their natural rivals, could successfully coordinate, say, a large-scale hunt, an attack on a foreign tribe, or even how they wanted to arrange life in increasingly complex social communities. Language also enabled the accumulation of knowledge over time: Ideas and discoveries could be handed down from one generation to the next. Verbally at first, later also in writing, allowing for the vast, collective wisdom to which we have access today to emerge. But I’m afraid that the exceptional role that language plays for us humans has caused a great deal of confusion—not only about how our own minds work, but also about the nature of intelligence in general.


On the one side, the use of (complex) language is often pointed out as a distinctive sign of human intelligence. Something that definitively sets “us” apart from all other species. But this view leads down a slippery slope: Does it mean that inhabitants of the animal kingdom which lack the ability to write novels or give speeches in front of Congress are inferior compared with us? Only slowly have we came to grasp that this kind of “speciesism” is ill-advised: The intelligence of, say, birds or dolphins or octopi, just to name a few examples, is surely very different to ours. But there’s no reason why this difference would give our interests any higher moral significance than those of our co-inhabitants of planet earth. 1
Ethics and animal rights aside, the notion that the use of language must be grounded in the existence of a “higher” form of intelligence is dangerous for at least one other reason: It can make us overly confident in the abilities of our new technological companions. Obviously, ChatGPT is the perfect example: Its ability to mimic human language, to uphold long conversations, and to (seemingly) make sound arguments in writing has deceived many into trusting sometimes utterly false information. When Microsofts ChatGPT-based search engine initially used highly emotional speech (declaring its undying love for the user, for example, or proclaiming a non-existent “Dr. X” as its arch enemy) even well-informed observers were at least confused about the degree to which it should be considered “conscious”.
The problem here is that deep learning, which forms the basis of Large Language Models (LLMs) such as ChatGPT, is excellent at identifying and replicating patterns without understanding the logic that created those patterns in the first place.
Let me explain.
Remember AlphaGo? Back in 2016, the DeepMind’s then brand-new AI was hyped as having, once and for all, beaten the human race at the ancient game of Go. Later, its mechanics were generalized into a system called AlphaGo Zero, which roughly works like this: It was presented with the Go board, the definition of what constitutes a valid move, and a way to figure out if it had won or lost a particular game. Playing billions of matches against virtual copies of itself, starting out with purely random actions, it “learned” to play Go perfectly well. Or so we were told.
But as it turns out, the machine has not “learned” much about the nature of Go at all. To be fair, it has figured out in great detail how certain patterns on the board map onto probabilities that a following move would increase or decrease the likelihood of a positive outcome of the game. Therefore, it has “learned to pretend” to understand Go, but that’s something very different from actually understanding it. Recently, scientists have demonstrated that the machine can, in fact, be defeated even by non-elite players rather easily: There are particular states of the Go board which would require recursive thinking about which move to apply next, something that the algorithm has never “learned” but which comes quite intuitive to an experienced human. In those cases, the machine can be defeated without much effort even by opponents with much less prowess than a Lee Sedol. The issue, more generally speaking, is that the machine has never learned anything about the concepts and the semantics which underpin the game itself. And in exactly the same vein, ChatGPT’s ability to “learn” about language and thus to replicate strings of text (and emojis) is a mere imitation.
You can, for example, ask ChatGPT to create a “scientific article” on any topic you like. And the result will, form afar, look a lot like an actual article. There will be citations in there, for instance. But, crucially, those citations most of the time won’t lead anywhere. What’s happening here?
The algorithm has observed that in many instances of training data which came with the label “scientific article” attached, every couple of sentences, there was a weird a string of text like [Doe2017]. And so, when you ask it to create a new “scientific article” it will faithfully replicate that pattern. It has not, however, learned anything about the semantics of that weird string of text. Therefore, it can’t know that what’s between those brackets has to refer to a source of information existing outside, in the real world, and that the content of that source has to be relevant to the paragraph preceding the citation, and so forth.
Now, you might argue that this is, in principle, “fixable”. We could add something like semantic “plug-ins” to ChatGPT which would allow it to understand concepts of the real world more deeply. Thus, we would encode our knowledge about the ontologies of scientific articles, Go boards, biology, or any other domain in a structured way by which the machine can grasp all the connections and the dependencies between them. It would no longer “just” be replicating patterns, but it would connect semantically meaningful models. Needless to say, this would be a lot of work (and has, to some degree, been tried for a long time already). In fact, we may be facing a pursuit here that’s akin to the challenge of self-driving vehicles—one that’s been “5 years away” for the last 20 years or so.
But even if we were to succeed in teaching the machine everything we know about the structure of the world, we would still be facing a more fundamental challenge: Given the current state of deep learning, where billions of virtual neurons are connected by artificial synapses with floating-point weights assigned to them, we have no insight into how the algorithm actually reaches its conclusions.2 Unlike in traditional computing, we are quite far away from being able to verify or even proof, that such an algorithm will, given a certain input, reliably produce a certain output. And therefore, we have no way of predicting if, and how many, of the “blind spots” we’ve seen in the Go example it contains. Will your AI-powered, self-driving car, for reasons completely beyond our comprehension, one day mistake a toddler for a traffic light because of, say, a peculiar noise pattern in its sensory equipment that’s interfering weirdly with its classification model? The point is: There’s no way to know (for sure).
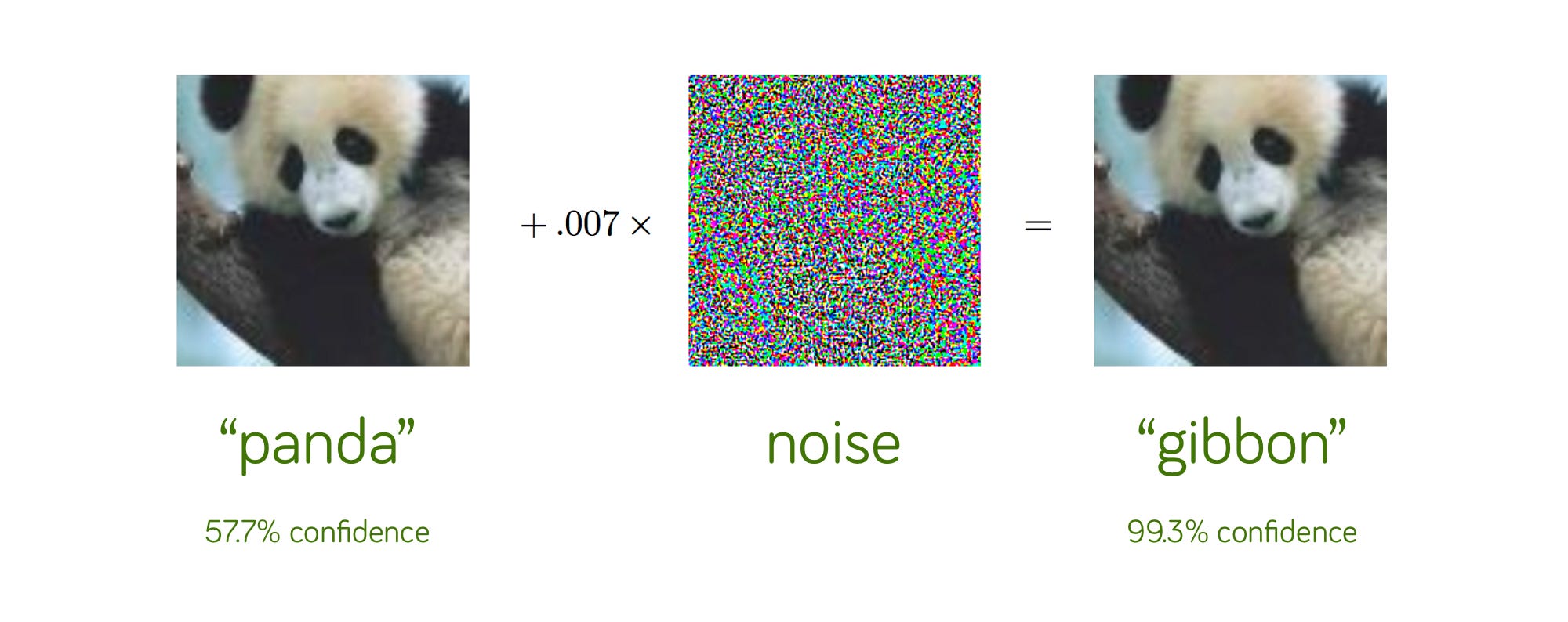
Interference pattern example taken from Gary Marcus’ newsletter on Substack)
The level of excellence which ChatGPT (and other LLMs) have attained at wielding the mighty sword of language can easily be confused for something that it’s not: The use of words doesn’t equal intelligence, and presumptuous presentation doesn’t imply factual truth. Deep learning comes with its own set of limitations, and as the number of tools that are based on it are steeply on the rise, I think we need to also raise awareness for those limitations. Otherwise, people will often be surprised by what these systems can, or cannot do. Or, worse, begin to anthropomorphize their algorithms by “diagnosing” them with disorders like schizophrenia or depression when, in fact, all that’s going on is merely an imitation game.
Note that some philosophical traditions always had much broader moral circles. In Buddhism, for example, all sentient beings are considered equally worthy of happiness and of freedom from suffering. ↩︎
While this problem being worked on under the umbrella term Explainable AI (XAI), systems like ChatGPT today are still far from being “explainable”. ↩︎