
Tracking the search engine market feels almost mesmerizing these days—a bit like staring into a lava lamp and wondering what’s going on in there. After Google having dominated the field practically forever, with Microsoft’s Bing struggling to even register as a contestant, competition apparently surged and almost immediately plummeted again. At first, it seemed as if Google had overlooked the potential disruption of the traditional, stateless search interface by conversational and interactive experiences that ChatGPT and others offer. Nevertheless, now that OpenAI, Microsoft’s “new” Bing, and newcomers such as you.com have attracted a lot of eyeballs, Google is expected to rush its Bard product to the market in an urgent attempt to catch up. But despite the broader question wether this launch frenzy will lead to an “AI arms race” with unforeseeable consequences, a more heterogenous search market has many upsides: At the end of the day, consumers are likely to get better search experiences of this, regardless which tool they prefer to use. And advertisers will have a real choice about which platforms they want to appear on—without forfeiting the lion’s share of web traffic if they’re not comfortable with Google Ads.
But technology-wise, I’m very much concerned that what we’re seeing here amounts to little more than putting lipstick on a pig. As long as the underlying paradigms don’t significantly change, particularly when it comes to how these systems understand all the information that’s out there on the web, as well as the meaning of the user’s query and their goals and intentions, we’ll remain stuck with inaccurate search results, with hallucinating chat bots, with irrelevant advertisements, and, most disconcertingly, with false information that’S presented as the gospel truth.
Let me illustrate what I mean with an example.
The other week, I was worried I might have wrecked the chain derailleur on my road bike. Quite at a loss what that thing exactly does, whether it was broken for real or if it could be easily re-adjusted, I headed over to my good old friend Google. Here’s what the world’s leading source of information came up with:
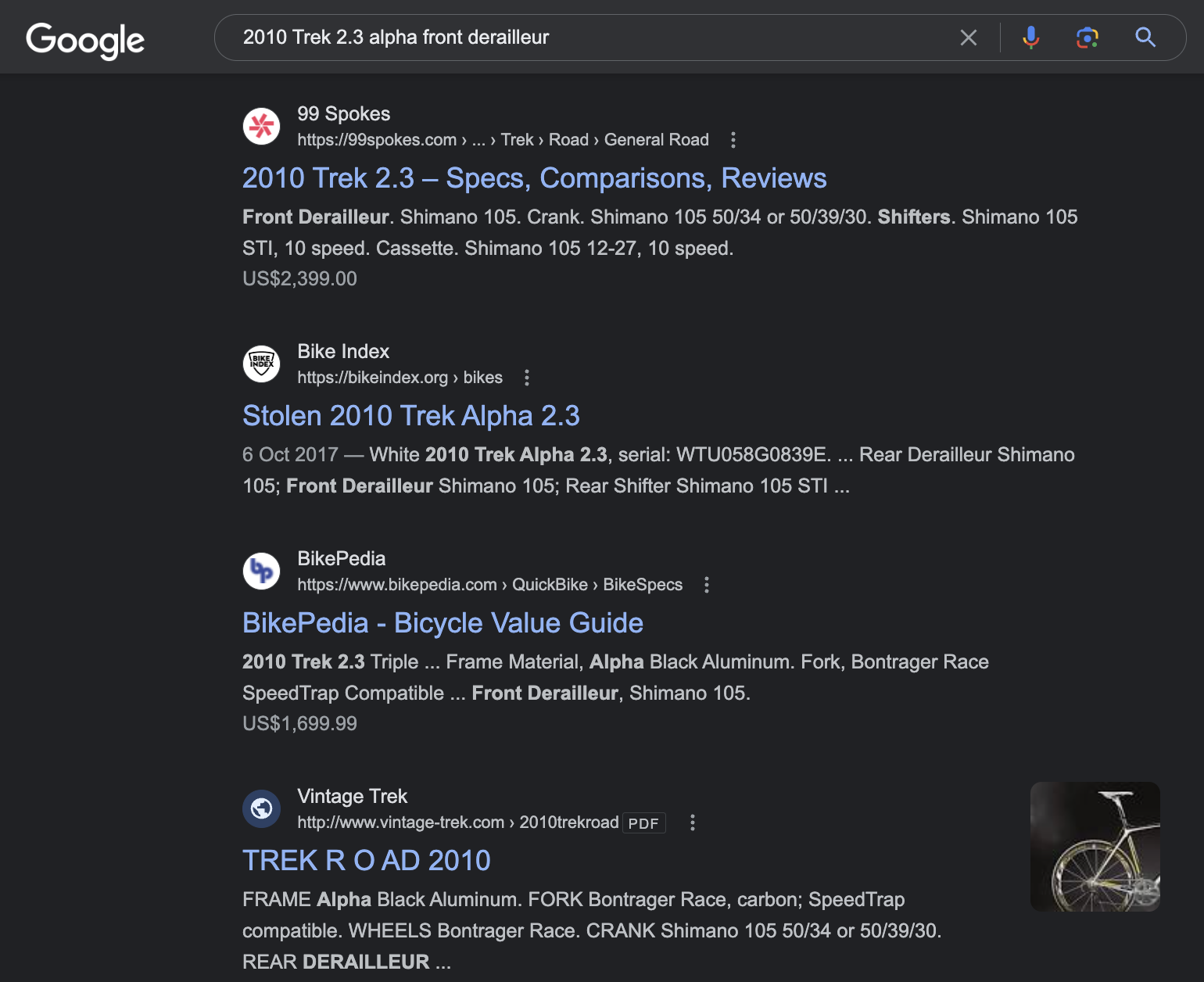
The organic results you see here are essentially a flat list of websites that mention some of the terms Trek 2.3 alpha and / or chain derailleur. There’s nothing wrong with that, but note that Google neither understands my intention, nor is it able to map any of the information that’s available on the web on to my specific problem: It doesn’t “know”, for example, that humans ride on bikes, that a Trek 2.3 alpha is an instance of bike, that bikes are made up of component parts, that those parts can become damaged over time and may need to be replaced or repaired, or that a chain derailleur is one such part. Lacking this understanding, the best Google can do is matching keywords with text, and spill out approximately 576,000 websites which contain some of the words I entered.
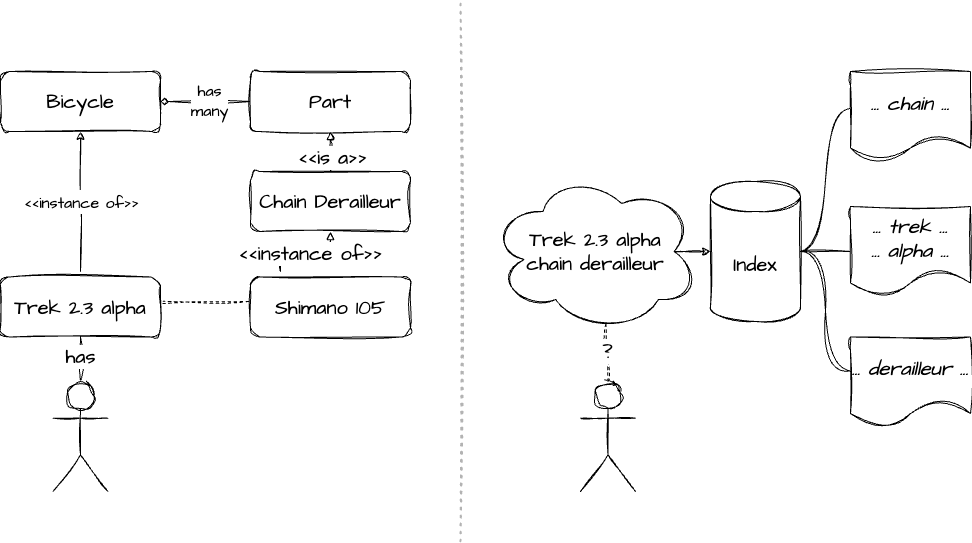
The difference between a semantic understanding of the world and matching keywords to text.
How could this be improved? Well, for example, if Google understood that a Trek 2.3 alpha is in instance of road bike it could immediately have blendet in much more actionable results, such as these:
But even more problematic (at least from Google’s point of view) is the quality of the sponsored product listings, i.e. the ads that it surfaces in order to drive their business model. Needless to say, the better the ads, the more likely it is that I’m going to click on them, and the more money Google is going to make. But notice how generic they actually are?
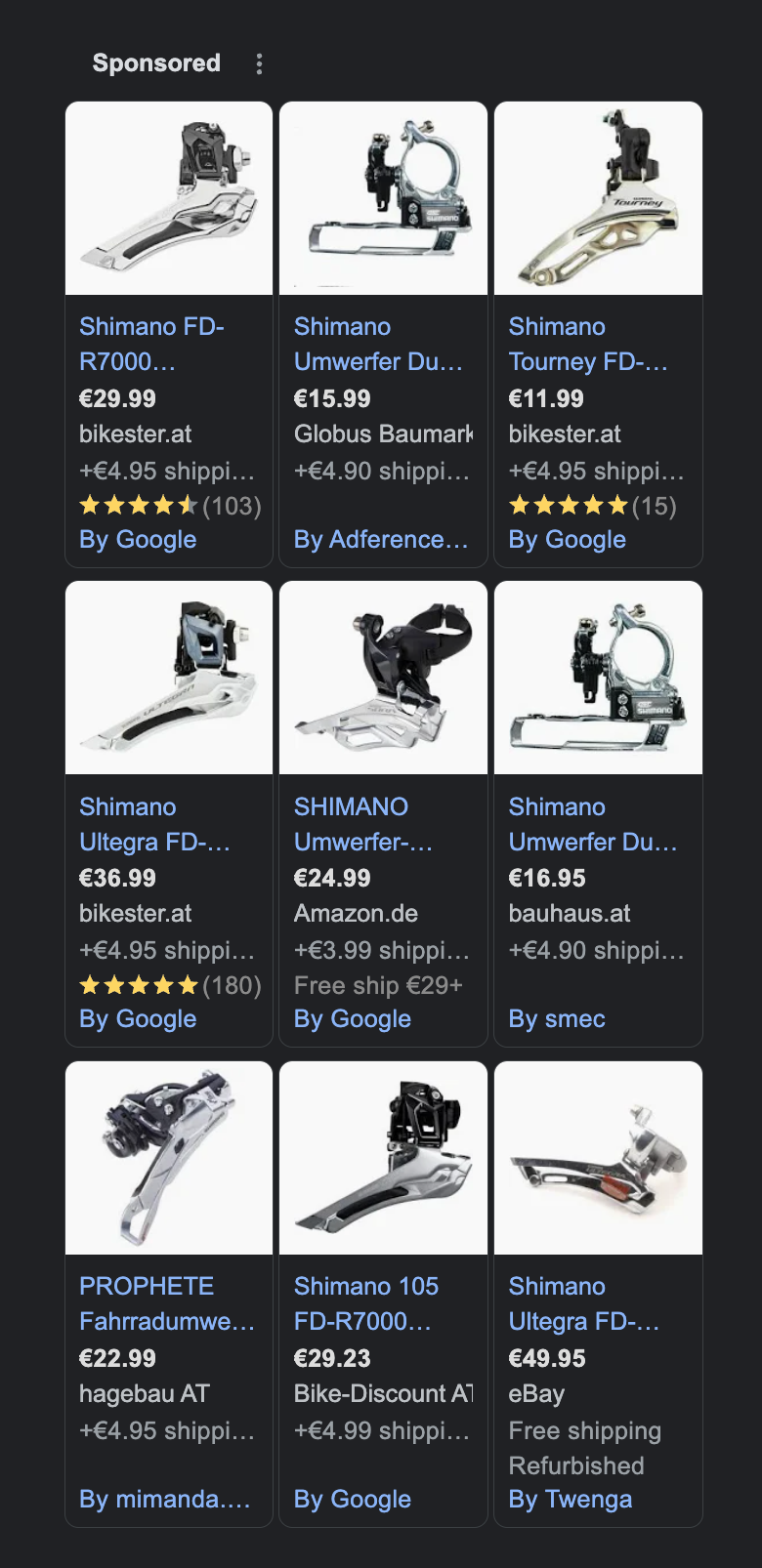
Yes, all of those are chain derailleurs. But how should I know if any of them will fit onto my specific bike? (As it turns out, there’s a gazillion variations of them, most of which are manufactured by Shimano and all have confusingly similar names.) And would I, as an amateur, even be qualified to replace that thing? Do I need a new rear derailleur as well then? And what about the chain?
So, as it turns out, these ads are pretty much useless to me, the potential buyer, at this point in my customer journey. I’m very unlikely to click on any of them (which would generate revenue for Google) or to purchase one of the products (which would generated revenue for the advertiser). And, sadly, that’s despite the fact that Google actually possess a lot of structured information about each of those products. For example, retailers have to provide minute details, including each product’s manufacturer, the price with and without tax, the shipping costs, etc., which Google apparently wants to integrate into what they call the “Shopping Graph”. But despite all of these efforts, it fails to build an understanding of the world that would allow it to connect the myriad of data points with my specific problem. What would such an understanding begin look like? Well, the information which exact chain derailleur fits on to which exact bike is publicly available on the Trek website. The information who sells which exact derailleur at what price point is provided by the retailers. The information which specific bike I have is provided… by me. But, sadly, there’s nobody out there who would connect the dots.
So, let’s head over to one of the upstart competitors in the search engine market, you.com1, to see if they venture any better at solving my bike troubles. It’s immediately obvious that the interactive, back-and-forth interface feels a lot more natural in this case than Google’s stateless search paradigm. But does it yield qualitatively better results?
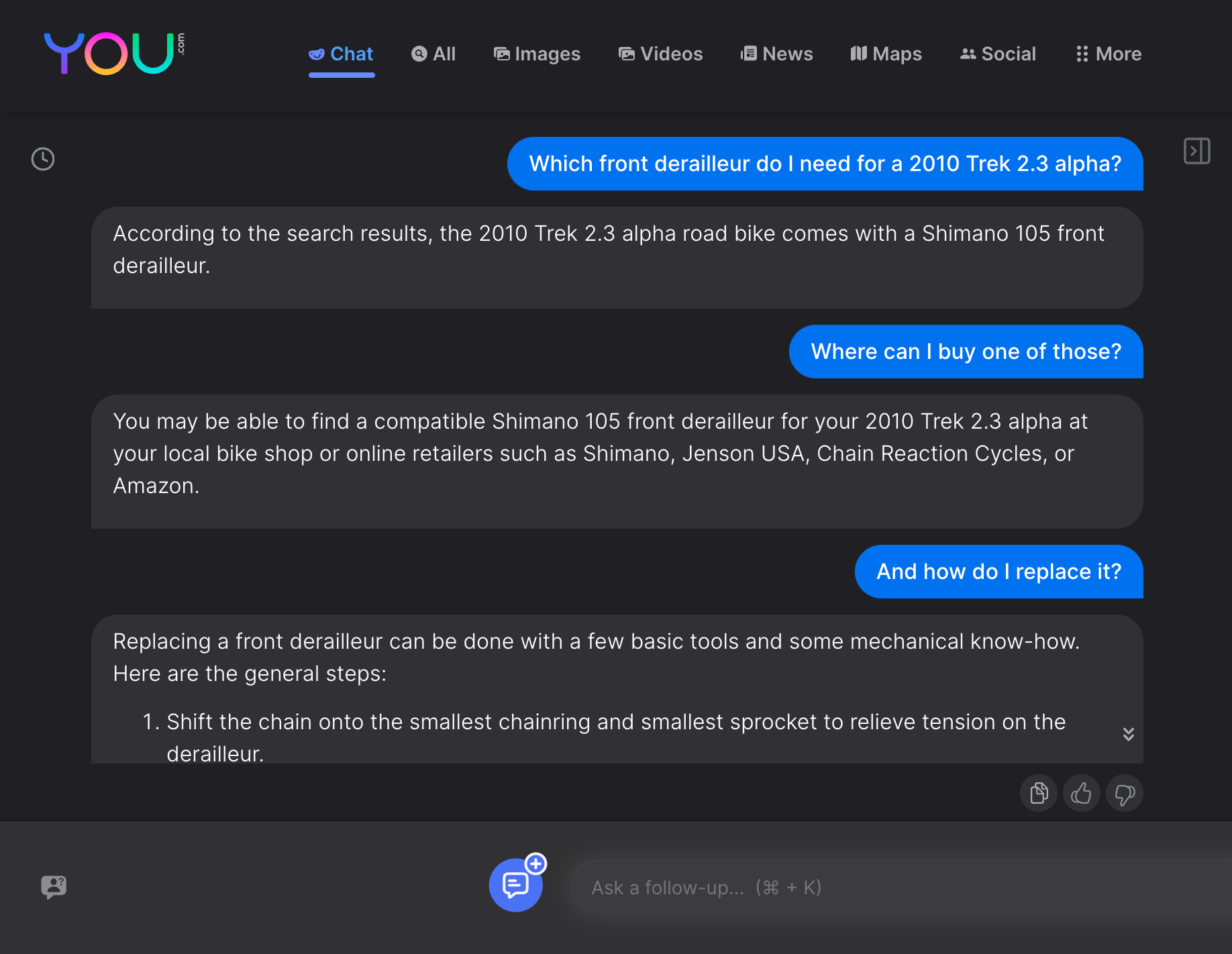
Now, say what you will, but that actually looks helpful. And it also shows how ads could be embedded much more organically at a suitable point in a conversational exchange, rather than being those awkward billboards that pop up somewhere on the side. As a consumer, I wouldn’t have minded a “sponsored” response being embedded somewhere, as long as it was clearly labeled, pointed to a trustworthy seller, and eventually got me the correct part at a reasonable price.
So, to sum it up, all will be well in search land from now on, won’t it? New, chat-based interaction models—powered by deep-learning-based LLMs—will produce more helpful organic results and more effective ads. Google will have a tough time for sure, but they’ll innovate to keep up. The search engine market will end up more balanced, and everyone, including consumers, advertisers, and the platforms themselves, will eventually be a lot better of.
Well, not so fast.
Here’s the problem: The results I got from you.com looked great at a first glance. And after some cross-checking I figured that they were factually not far from accurate. But what would have happened if I had initially used a slightly different prompt? Say, by asking for a chain derailer instead of a front derailleur, a mistake that could have easily happened to a cycling novice like myself. (After all, that’s why I’m looking for help online.)
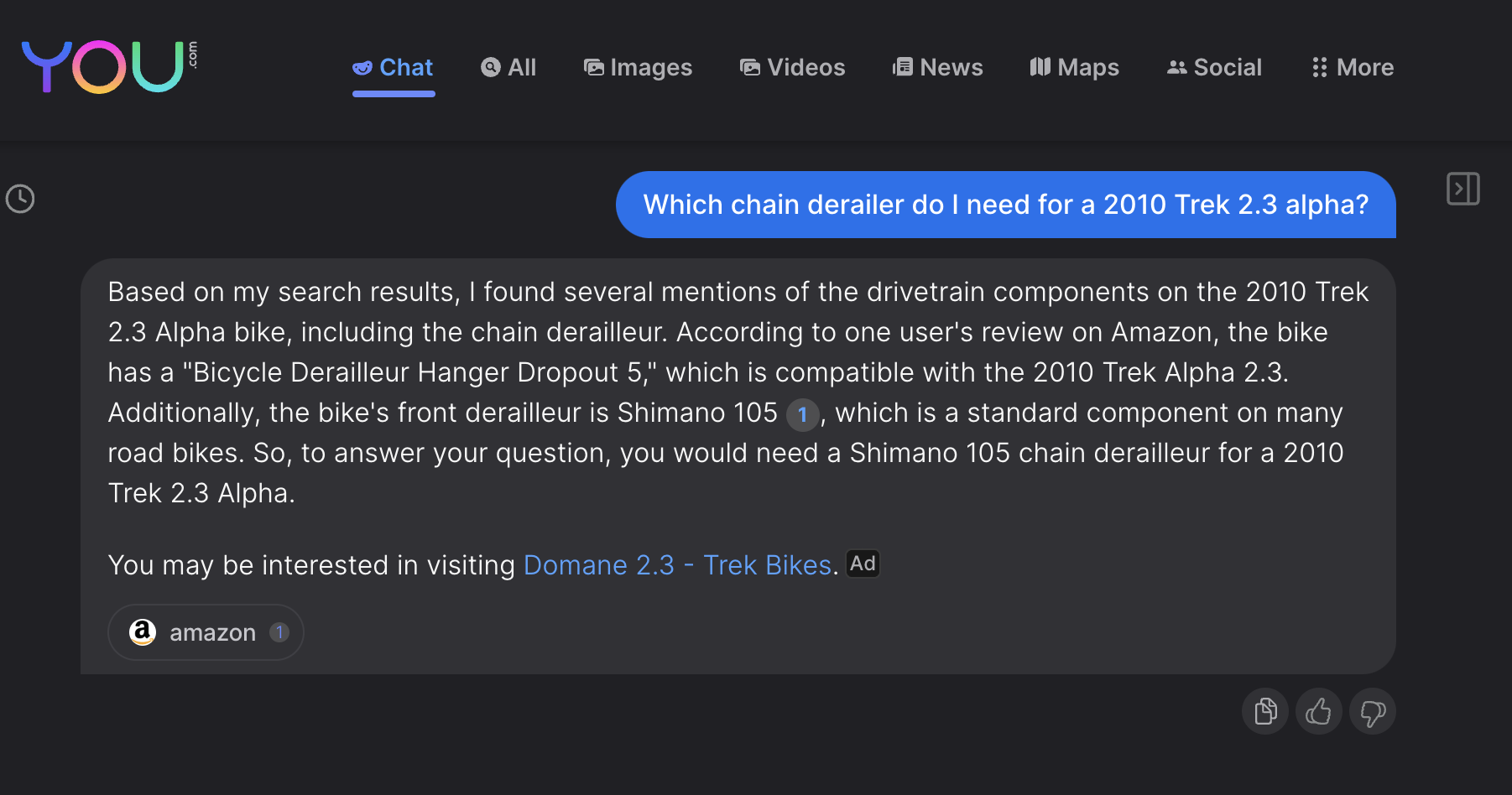
Let the second sentence here sink in for a moment:
According to one user’s review on Amazon, the bike has a “Bicycle Derailleur Hanger Dropout 5,” which is compatible with the 2010 Trek Alpha 2.3.
What does that even mean? The that bike comes with a derailleur hanger (which is, as it turns out, the part which holds the derailleur in place) called “Dropout 5”? And that that’s “compatible” with… the bike itself? And your source for that piece of wisdom is one guy’s review on Amazon? None of that makes a lot of sense, and it points to the same, underlying problem that we’e seen with the mediocre results that Google produced: The tool has no clue about the world. But instead of locating strings of text in a humongous database, it uses fancy statistics (think linear algebra) and deep learning to identify correlations in heaps of unstructured data. That, however, doesn’t change the fact that neither of those approaches possess any understanding of the real world in which there are humans, bicycles, chain derailleurs, and an endless amount of other things that have incredibly complex relationships with one another.
You might object that yes, in the end, it also arrived at the correct conclusion (the Shimano 105 is, after all, what I was looking for). But how much can you really rely on the factual correctness of that information if it’s only the result of some statistical analysis? As you’ve seen, the prompt-based interface is highly brittle despite appearing quite confident. But a small change in input can yield a different result, leaving the user at a loss which one, if any, is ultimately correct.
Now, it’s one thing if I end up ordering the wrong part for my 13-year old bike. 30€ down the drain and an afternoon full of tinkering and cursing is hardly going to kill me. But consider the myriad of use cases that people already turn to Google for today: We’re getting medical, financial, or legal advice. We’re researching how to best spend our holidays. What to eat. How to exercise. Whom to vote for. Much of the stuff that’s going on online influences life-changing decisions, and those better be based on information which is both accurate and trustworthy. As we’ve seen, it’s increadibly hard for Google and its upstart competitors to reliably meet those criteria today. But where are we headed if such murky results are no longer presented as a “take it or leave it” flat list, but are embedded into what, to many, seems to be a conversation with an totally sanguine, highly dependable, and fully omniscient being?

Unfortunately, how machines understand the world is not going to improve overnight. Whether it’s finding keywords in text or identifying statistical correlations, these approaches have proven to be “good enough” for a wide variety of use cases, which is why comparatively little progress has been made on alternative ideas. Gary Marcus and Ernest Davis, in their 2019 book “Rebooting AI”, have highlighted additional flaws and fundamental limitations of deep learning and related techniques, but they also sketched some potential solutions. For example, the machine learning community’s recent emphasis on building “end-to-end” models, whereby huge, monolithic neural networks are constructed which map complex inputs (such as a self-driving car’s streams of sensory and video data) directly onto an output (e.g. if the car should accelerate, break, or steer left or right) has overshadowed the well-established engineering practice of decomposing large problems into smaller ones which can be solved and verified independently. But, and this is also Marcus’ and Davis’ main point, even the most well-designed neural networks won’t magically develop what we would call “common sense.” That’s going to take a lot of time, effort, and resources. And it’s something that can’t be address by today’s cure-all solution of “throwing more data at it”. But a true understanding of the world, and of (at least) a fraction of the entities that inhibit it and how they relate to each other, is going to be crucial if we want the next generation of AI systems to be reliable and trustworthy. And it better be, if we use them to make more consequential decisions that which chain derailleurs to mount on our bikes.
For all intents and purposes, Bing would have worked just as well. But I wanted to give an underdog a chance to shine here. ↩︎